Objectif de la compression ↪ réduire la longueur d’une séquence numérique (en binaire) sans affecter son contenu informatif (= conservation de l’information)
➡ Transformer l’information délivrée par la source numérique ↪ on doit éliminer les redondances = représentation efficace
Le but est donc :
- de diminuer les tailles de fichiers et l’espace mémoire
- d’augmenter la capacité de transmission (en télécom, afin d’avoir un débit + important)
Il existe 2 types de compression :
- Compression sans perte ↪ on retrouve l’intégralité des données stockées sous forme comprimée (par exemple : billets pour un concert, déclaration d’impôts, bulletins de votes)
- Compression avec pertes ↪ un peu de distorsion donc perte d’information mais plus complexe (par exemple : émissions podcasts, musiques au format mp3, photos, vidéos…)
Ici, on ne verra que la compression sans perte.
Codage de caractères
Introduction
Dans les exemples, nous verrons comment compresser du texte, donc il est important de voir comment on peut coder ce texte.
Les ordinateurs utilisent des données binaires, donc chaque caractère de texte va être codé par 1 nombre, donc par une suite de bits.
Il existe différents codages de caractères (évolution avec le temps et différente selon les langues)
codage Baudot (1874) : premier code binaire destiné à être utilisé par une machine
Code ASCII1
Développé dans les années 1960, norme ISO 646 en 1983
Codage qui utilise 7 bits pour représenter un caractère, donc permet de représenter caractères différents ce qui représente :
- 26 lettres latines minuscules
- 26 lettres latines majuscules
- 10 chiffres décimaux
- espace
- ponctuation
- parenthèses
- codes de formatage (retour à la ligne, DEL, ESC)
Format : 1 octet par caractère (8ème bits soit à 0, soit un bit de parité pour détecter les erreurs selon les systèmes de transmission : pour l’uniformisation des données)
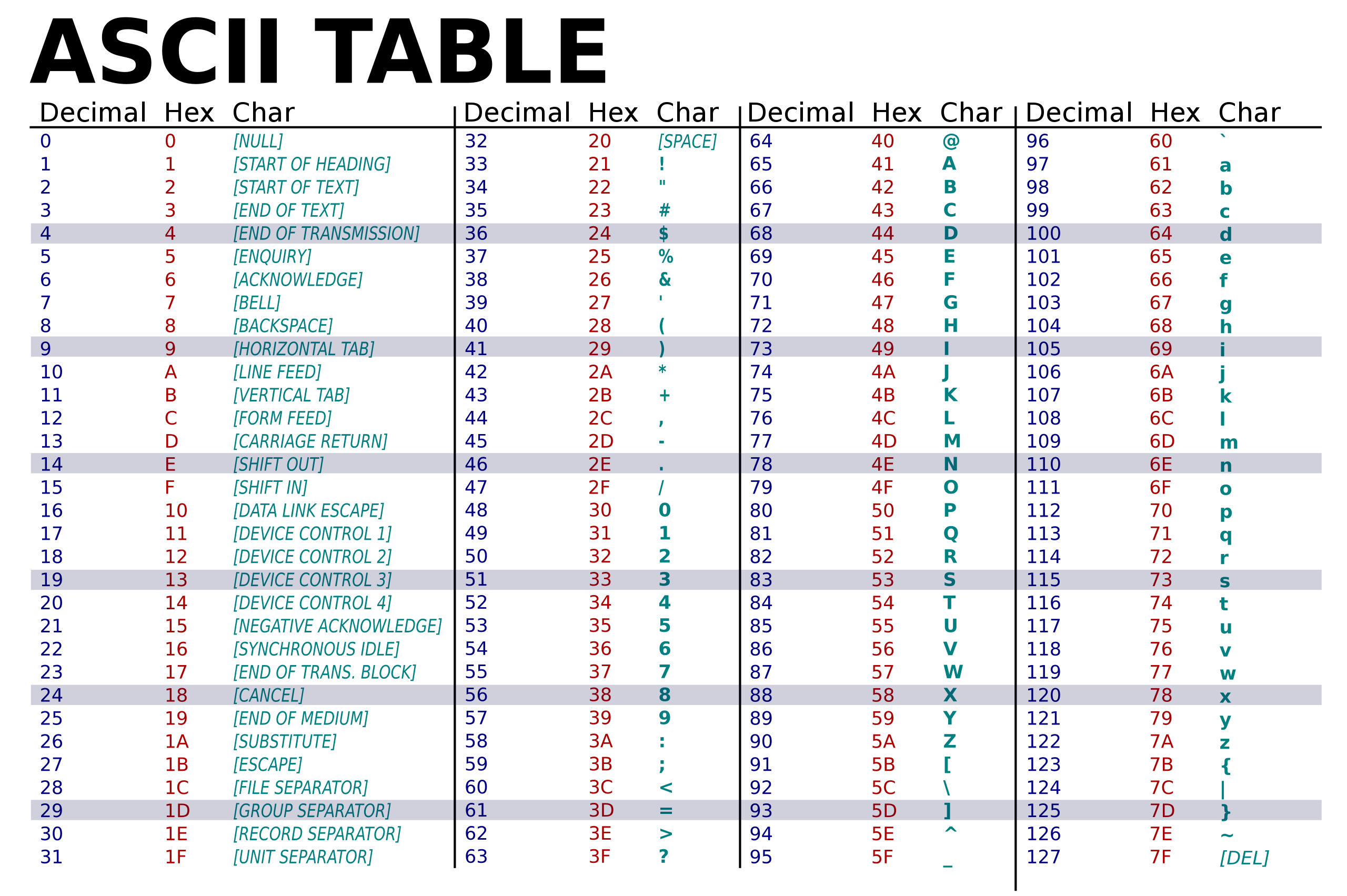
Convertir "Je" en ASCII
J = 4A en Hexa
e = 65 en Hexa
Donc la suite de bits est : 0100 1010 0110 0101
Limites du code ASCII
- Nombre limité de caractères
- Manque de caractères importants : * au lieux de
- code américain donc pas de caractères accentués
- pour les autres alphabets (grecs, arabe, chinois) ↪ inadéquat
Donc développement d’autres codages de caractères
Autre codage de caractère (UTF-8)
ISO2 8859
- Versions ASCII étendues : Compatibilités ascendante et descendante (programme de lecture ISO8859 peut lire de l’ASCII et programme ASCII peut lire ISO8859)
- Version la plus utilisée ISO8859-1 souvent dénommée Latin-1 (Europe Occidentale)
- 191 caractères codés sur un octet (au lieu de 128) ;
- Versions ISO8859-2 (Europe de l’est), -3 (Europe du sud), -4 (Europe du nord), -5 (pour le russe), -6 (pour l’arabe)
- Nombreuses versions non compatibles entre elles et insuffisant pour les langues à idéogrammes
Unicode (1987)
- Créer un code universel
- Augmenter le nombre de bits pour coder un caractère ↪ 16 bits (65536 caractères)
- Inconvénients : 2 fois plus gros et non-compatible avec ASCII
- Est devenu une famille de codage
- En 1991, consortium Unicode, la norme Unicode, en plus d’un standard de codage de caractère, un immense rapport sur les langues.
- La version 10.0,(8 518 nouveaux caractères) pour un total de 136 690 caractères est publiée le 20 juin 2017
- Plusieurs encodage existent ↪ le plus connu UTF3 qui est compatible avec ASCII
UTF-8
Codage de longueur variable :
| Nombre d’octets | Caractères codés |
|---|---|
| Sur 1 octet (0x00 à 0x7F) | tous les caractères du ASCII (MSB4 à 0) |
| Sur 2, 3 ou 4 octets | les autres caractères (MSB à 1) |
Codage de l'UTF-8
Un premier octet (lead byte) suivi d’un nombre variable d’octets (trailing byte)(maximum 4 octets au total) représentent conjointement la valeur à encoder.
Bit de poids fort du lead byte à 1 et autant de bit à 1 que de trailing byte.
Un même caractère peut avoir plusieurs représentations choix du code le plus court
| Formats du code | Nombre d’octets utilisés | Nombre de bits disponibles pour coder | | ----------------------------------- | ------------------------ | ------------------------------------- | | 0xxxxxxx | 1 | 7 bits | | 110xxxxx 10xxxxxx | 2 | 8 à 11 bits | | 1110xxxx 10xxxxxx 10xxxxxx | 3 | 12 à 16 bits | | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 | 17 à 21 bits |
21 bits sont suffisants pour représenter l’ensemble des caractères définis par l’Unicode
Coder " été"
En UTF-8 : C3 A9 74 C3 A9
C3 A9 = 1100 0011 1010 1001 avec le lead byte et le trailing byte (donc “é” codé sur 2 octets)
Taille des fichiers
Plus on utilise des caractères peu fréquents (comme les caractères accentués), plus le nombre d’octets utilisés est grand donc plus le fichier en sortie est volumineux
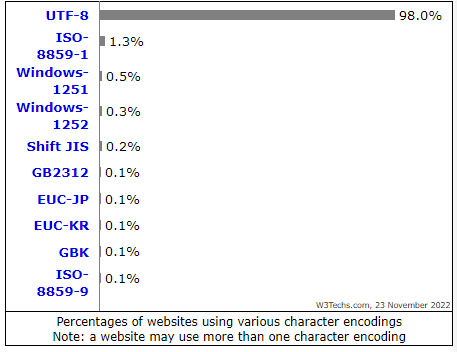
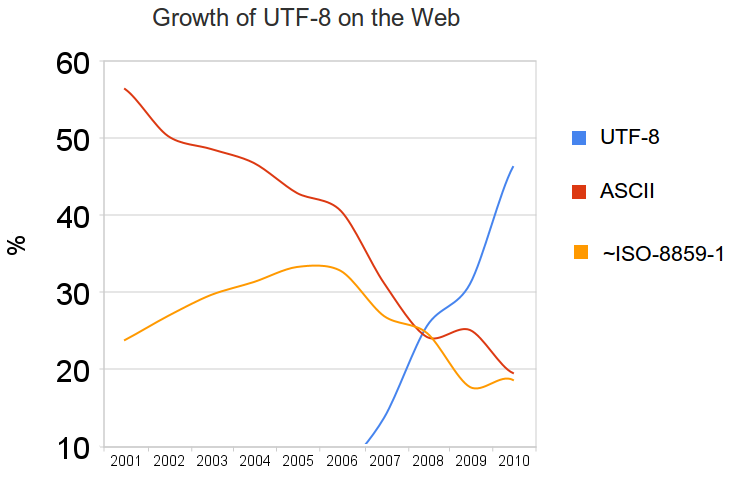
L’UTF-8 domine le web, c’est le codage le plus utilisé actuellement (source)
Compression
Introduction
La distribution des lettres n’est pas équivalente en française (ou dans d’autres langues) :
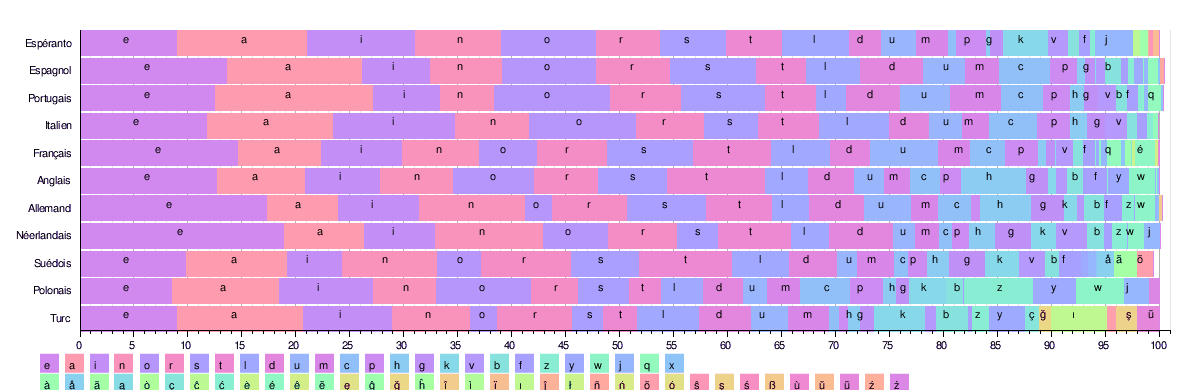 Par exemple, la lettre e est utilisée 15 fois plus souvent que la lettre de b.
Par exemple, la lettre e est utilisée 15 fois plus souvent que la lettre de b.
Premières compressions : Morse, avec les lettres les + utilisés : e, a, t (on voit qu’elles ont un plus court symbole)

Définitions
- La compression transforme l’information délivrée par la source numérique
- Elimine les redondances ↪ pour minimiser la longueur binaire moyenne d’un code

Notations utilisées en compression
Longueur binaire d’un symbole codé : nombre de bits d’un symbole codé (le symbole “a” en ASCII est 01100001 donc )
Probabilité pi de chaque symbole du code :
Taille (longueur moyenne pondérée) du code de Q symboles :
Donc, pour réduire , on va chercher à réduire quand est élevé et inversement
Code à 6 lettres
Lettre A B C D E F Code 0 1 00 01 001 101 Apparition 5 4 3 2 1 1 Probabilité 5/16 4/16 3/16 2/16 1/16 1/16 1 1 2 2 3 3 Calcul de
1,56 bits / symbole
Différents codes et leurs caractéristiques
Symboles Code A Code B Code C Code D 0,5 00 0 10 0 0,3 01 1 00 10 0,1 10 00 11 110 0,1 11 11 110 111 Le code A a une longueur moyenne de 2 bits/symboles et est à longueur fixe et c’est un code préfixe
Le code B a une meilleure compression (1,2 bits/symbole) mais est à longueur variable et c’est un code non préfixe (S1 et S3 commencent par le même symbole)
Le code C a une longueur moyenne de 2,1 bits/symbole et est à longueur variable et non préfixe
Le code D a une longueur moyenne de 1,7 bits/symbole est à longueur variable et est préfixe
Code à longueur fixe et variable
A longueur fixe : nombre de bits fixé (ASCII)
A longueur variable : nombre de bits variables (Morse)
Code préfixe (ou code instantané)
Un code préfixe est un code où aucun symbole n’est le préfixe d’un autre, donc tous les mots du code peuvent être décodés sans erreur. Tous les codes à longueur fixe sont des codes préfixes
On préfère utiliser des codes préfixes pour la compression, comme UTF-8
Information associée à un symbole
Soit A le symbole dont la probabilité d’occurrence est . L’information liée à A est :
Donc, si A est peu probable, , et si A quasi certain,
Donc, plus est élevé, plus sera faible (donc l’information est liée à la rareté d’un symbole)
Exemple de calcul d'information des symboles
Symboles Code A Code B Code C Code D 0,5 00 0 10 0 0,3 01 1 00 10 0,1 10 00 11 110 0,1 11 11 110 111
Entropie H : information moyenne liée au code
L’entropie représente la moyenne pondérée de l’information et est définie par :
L’unité de H est en bits d’information / symbole transmis, ou en Sh (Shannon)
Les valeurs extrêmes de l’entropie sont :
- pour (1 seul symbole présent)
- pour Q symboles équiprobables, donc
Exemples de calcul d'entropie (avec 16 lettres)
- A A A A A A A A A A A A A A A A
donc l’entropie est
A B C D E F G H I J K L M N O P
donc donc entropie maximale
Origines de la notion d'entropie
Bilan sur l'entropie
A B C D E F G H I J K L M N O P ↪ H = 4 bits/symb
I L F A I T B E A U A I B I Z A ↪ H= 2,875 bits/symb
A A A A A A A A A A A A A A A A ↪ H = 0 bit/symb
Entropie forte : Plus il y a de lettres différentes, plus il y a de désordre, plus il y a de nouveauté, plus il y a d’« information » dans le message
Entropie faible : Plus il y a de lettres semblables, moins il y a de désordre plus il y a de redondance et donc moins d’« information » dans le message.
Inégalité de Kraft
L’inégalité de Kraft est un résultat fondamental en théorie des codes, c’est une condition nécessaire et suffisante d’existence d’un code déchiffrable et instantané
Un code instantané doit satisfaire cette inégalité :
La réciproque est vraie, si une suite de vérifient cette relation, alors il existe un code instantané avec cette distribution des longueurs

Autres définitions
Taille du code
- Pour un code à longueur fixe, la taille du code est la taille des mots (ASCII = 8 bits)
- Pour un code à longueur variable, la taille du code est
Théorème de Shannon code préfixe
Plus (dépend de la compression utilisée) est proche de (qui ne dépend que des probabilités des symboles), meilleure seront les performances de la compression
Efficacité et taux de compression
L’efficacité est définie par :
Le taux de compression est :
Exemples
Symboles Code A Code B Code C Code D 0,5 00 0 10 0 0,3 01 1 00 10 0,1 10 00 11 110 0,1 11 11 110 111 On a : bits/sym, bits/sym, bits/sym, bits/sym. Codes non préfixes donc inutilisables pour appliquer l’inégalité de Kraft
On calcule l’entropie : bits/symboles
Donc on a bien : , et on voit que est plus proche de que , donc le code D apporte une meilleure compression
Codages de compression statistique
Introduction
Compressions avec algorithmes statistiques
- Pour les données aléatoires ↪ sans corrélations entre elles
- basées sur les fréquences d’apparition des symboles
- attribuer un code binaire d’autant plus court que le symbole apparaît souvent et inversement (appelé VLC7) ↪ donc code à longueur variable
Deux algorithmes : de Shannon-Faro et Huffman
But des codages de compression statistique
- Associer de manière optimale (le mieux possible) des mots aux symboles (utiliser les caractères dans les exemples)
- Mettre en œuvre des codes de longueur variable pour réaliser des codes de longueur moyenne minimale
- Réaliser des codes qui ne soient pas ambigus (code préfixe)
Codage de Shannon-Fano
Méthode du codage de Shannon-Faro
- Calculer les fréquences d’apparition des symboles (=probabilité)
- Les trier par ordre décroissant dans un tableau
- Diviser ce tableau en deux partie équivalentes (obtenir la somme de fréquence ou probabilité la plus égale entre les parties)
- Affecter 0 à la moitié inférieure et 1 à la moitié supérieure
- Recommencer en re-divisant chaque partie du tableau de manière équivalente
Exemple avec un code à 5 lettres
1 et 2 : trier par ordre décroissant
Divisions en parties équivalentes :
Donc le code final est :
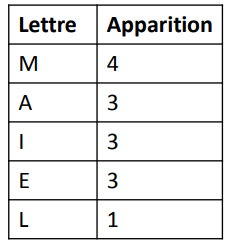
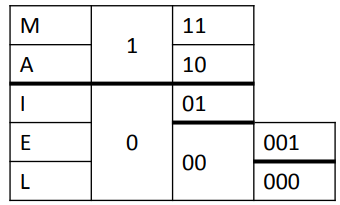
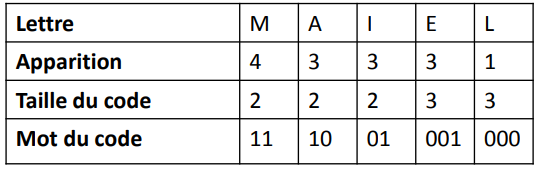
Le codage de Shannon-Fano est un algorithme simple avec des performances élevées. Mais c’est un code sous-optimal (pas optimisé dans le sens statistique) en terme de longueur moyenne des mots code. Donc, pour assurer l’optimalité : code de Huffman
Codage de Huffman
Ce codage a été créé par David A. Huffman, et est par exemple utilisé pour le format .zip
L’idée de ce code est de coder ce qui est fréquent sur peu de place et coder en revanche sur des séquences plus longues ce qui revient rarement. Ce code utilise une création d’un arbre, et l’encodage du texte se fait selon l’arbre.
Vocabulaire du code de Huffman
Feuille de l’arbre = nœuds initiaux : un caractère et sa fréquences (probabilité d’apparition)
Branches : lien entre les nœuds. Par convention :
- les branches à gauche : code 0
- les branches à droite : code 1
Racines de l’arbre : dernier nœud
Illustration d’un arbre du code de Huffman :
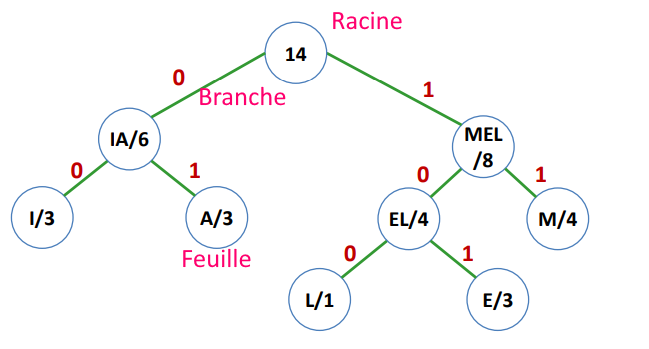
Méthode du codage de Huffman
- Tableau des fréquences d’apparition des symboles
- Tant qu’il y a plus d’un nœud :
- Faire 2 nœuds de plus petites probabilités reliés par des branches (0 ou 1)
- Faire un nouveau nœud qui relie ces nœuds avec la somme des probabilités
- Réordonner la nouvelle liste
- Dernier nœud = racine (somme des probabilité = 1)
- Les chemins des la racines jusqu’au “feuilles” donnent le code des symboles
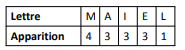
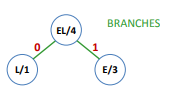
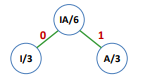
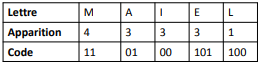
Exemple avec un code à 5 caractères
Avec les lettres telles que :
On effectue d’abord :
Puis :
On répète l’opération pour toutes les lettres restantes, et on obtient donc :
Le codage correspondant est alors :
Sur les codages
- Il est nécessaire de pouvoir lire tout le fichier avant de le comprimer (afin de connaître les fréquences)
- pour décoder, il faut évidemment avoir le même arbre (il faut s’être mis d’accord des deux cotés au préalable : on ne « unzip » pas un fichier « .rar »)
- pour décomprimer il faut connaître les codes et donc la table, ajoutée devant le fichier, aussi bien pour transmettre que stocker ↪ diminue la compression surtout pour les petits fichiers.
- Plusieurs variantes du code de Huffman existent
Ne pas confondre les 2 codages
Huffman Shannon-Fano Addition des probabilités Division des probabilités Commence par les plus petites probas Commence par les plus grandes probas
Codages par substitution
Précédemment on a vu les compressions avec des algorithmes statistiques.
Les compressions avec des algorithmes dynamiques se font avec :
- des données redondantes : certaines séquences de symboles se répètent plus ou moins régulièrement ↪ leur attribuer un code spécifique bien plus court ⇒ réduire la taille occupée
- RLE et compression par dictionnaire Lempel et Ziv
Codage RLE8
Codage basé sur la redondance
Principe du RLE
- Suite de bits ou de caractères identiques remplacée par un couple (nombre d’occurrences ; bit ou caractère répété) (par exemple : dddddddddd ↪ 10d)
- Le résultat comporte en général moins de caractères
- AAAAAAAAZZEEEEEER ↪ 8A2Z6E1R ↪ beaucoup plus court
- WBWBWBWBWB ↪ 1W1B1W1B1W1B1W1B1W1B ↪ deux fois plus long
- Nécessité d’un caractère spécial pour annoncer une répétition (par exemple : @10d)
- C’est une compression pour plus de 3 répétitions :
- aa ↪ 2@a (3 bits > 2 bits : ✖compression)
- aaa ↪ 3@a (3 bits = 3 bits : ✖compression
- aaaa ↪ 4@a (3 bits < 4 bits : ✔ compression)
Compression par dictionnaire Lempel et Ziv
Fonctionne sur le même principe que le RLE
Principe de la compression par dictionnaire
- Remplacer des séquences ou termes par un code plus court appelé l’indice de ce terme dans un dictionnaire.
- Sauvegarder des chaînes de caractères dans un dictionnaire et les indexer
- Lorsqu’on trouve un mot dans la liste, remplacer ce mot par sa position dans la liste.
- Deux types de fonctionnement :
- Dictionnaire calculé une fois pour toute
- Dictionnaire qui évolue
- Nature du dictionnaire : dépend des applications (textes, binaires, codes sources…)
Vient de Jacob Ziv and Abraham Lempel (1970) ↪ LZ77, LZ78 et LZW
1ère méthode : LZ77
Le dictionnaire est une portion du texte à encoder
- Fenêtre glissante avec 2 parties
- Buffer de recherche (dictionnaire)
- Buffer de lecture
- Le dictionnaire contient les chaînes les plus récentes présentes dans la fenêtre glissante
- Evolution perpétuelle du dictionnaire
En sortie, on obtient un triplet (P,L,C) avec :
- P = distance entre le début du Buffer de lecture et la position de répétition
- L = longueur de la séquence commune
- C = caractère suivant dans le Buffer lecture
2ème méthode : LZ78
Algorithme LZ77 : trop peu de mémoire (ne garde que les N derniers caractères)
L278 :
- pas de fenêtre coulissante
- dictionnaire constitué à partir de tout le texte au fur et à mesure
Au départ, aucun terme connu ↪ on ajoute au dictionnaire tous les termes rencontrés en les numérotant
On cherche le plus long terme en correspondance avec un terme du dictionnaire
3ème méthode : LZW
Proposé par Terry Welch en 1984
LZ78 écrit trop de caractères ↪ pour faire mieux, à l’initialisation dictionnaire = toutes les lettres de l’alphabet (tous les caractères ASCII)
Pour un nouveau mot du dictionnaire : tous ses préfixes présents
Lecture du caractère du mot à coder ajouté au mot surveillé actuel (au départ : mot vide)
2 cas :
- Mot présent dans le dictionnaire
- Recommencer en lisant la lettre suivante
- Mot non présent dans le dictionnaire
- Ajouter au dictionnaire
- Coder le mot sans la dernière lettre avec son index
- lecture avec cette dernière lettre lue (première lettre non codée)
En sortie : un indice I qui est l’index du terme dans le dictionnaire
Conclusion
Plusieurs critères pour qualifier la compression :
- taux de compression
- avec ou sans perte (= destructive ou non)
- temps de compression
Tout algo de compression possède un algo de décompression correspondant
Compression de données sans perte
- réduit la taille des données en supprimant les redondances
- processus réversible, valable pour tout type de données, gain théoriquement assez faible
- compress d’
UNIXet formatGIF9 ↪ Algo LZW (plus efficace que l’algo RLE pour BMP) PNGetgziputilisent l’algo Deflate = combinaison des algo LZ77 et Huffman
Compression avec perte
- Compression dégradante, suppression des informations “peu significatives, inutiles”
- Compression non réversible, gain de compression très grand
Format JPEG[^10] : formules mathématiques complexes ↪ enlever les détails non visibles à l’oeil (même principe pour les mp3)
[^10] : Joint Photographic Expert Group
Format MPEG[^11] : compression de la vidéo ↪ détecter des corrélations dans les données (informations redondantes)
- corrélations spatiales : des formes qui se répètent, des motifs
- corrélations temporelles ↪ éléments semblables d’une image à l’autre (détection de mouvement) [^11] : Moving Photographic Expert Group
Footnotes
-
American Standard Code for Information Interchange ↩
-
International Organization for Standardization ↩
-
Universal Transformation Format ↩
-
bit de poids fort : non utilisé en ASCII ↩
-
ardent défenseur de l’existence des atomes père de la physique statistique ↩
-
mathématicien, ingénieur électricien, cryptologue père de la théorie de l’information ↩
-
Variable Length Code ↩
-
Run Length Encoding ↩
-
Graphic Interchange Format ↩