Problème = question à laquelle un ordinateur devrait être en mesure de donner une réponse
Algrorithme = processus systématique pour résoudre un problème
Problèmes
Il existe des problèmes indécidables : sans solution algorithmique
Problème de l'arrêt
étant donnés un programme P et une donnée d’entrée d, est-ce que l’exécution de P s’arrête pour l’entrée d ?
Critères de comparaison des algorithmes
simplicité, compréhensibilité
nombre de lignes de l’algo
temps de calcul : complexité en temps (privilégié dans cette UE)
prédire la consommation énergétique d’un programme
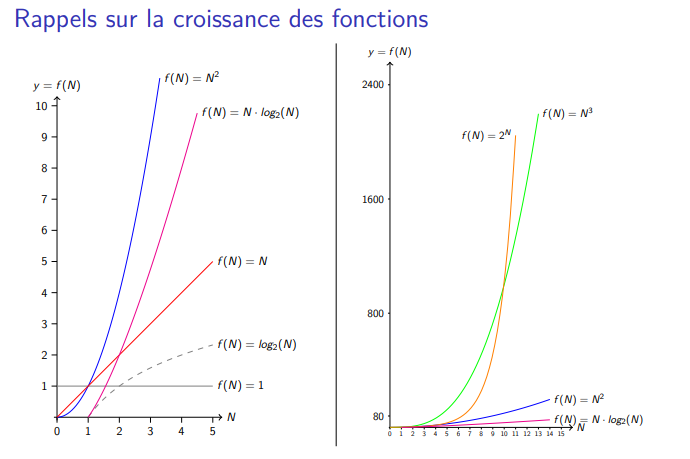
Comment calculer la complexité en temps d'un algorithme
N = taille de la donnée manipulée par l’algo
Montrer que le nombre d’opérations effectuées par l’algo est proportionnel à l’une des fonctions : 1,N2,log2(N),N,N3,N×log2(N),Nk,2N
Estimer le nombre d’opérations effectuées par l’algo avec une fonction f(N)
estimer la puissance de clacul P de la machine utilisée (en FLOPS)
FLOPS : Floating Point Operation per Second
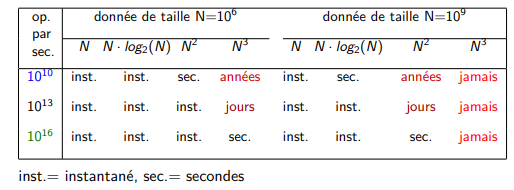
Ordinateur portable : 70 Giga FLOPS = 7 · 1010 opérations par seconde Consommation : 200 Watts
Record 2016 : Wuxi (Chine), 90 Peta FLOPS = 9 · 1016 op. par sec. Consommation : 15 MWatts (une ville de 18.000 habitants)
Pour un N donné, le temps de calcul est f(N)/P
exemple de temps de calcul en fonction de la taille des données
Dérouler l’exécution d’un algorithme
Principe des déroulages concrets
Quand on rentre dans une fonction, on trace une ligne verticale parallèle au code de la fonction
Si une instruction donne la valeur v à une variable x on écrit x=v en face de cette instruction
Si une condition est vraie (ou fausse) on écrit cond: true en face de l’instruction testant la condition
Si on rentre ou si on itère sur une boucle, on trace une nouvelle ligne verticale parallèle à la précédente
Par exemple :
Problème de la recherche
Problème de la recherche
Etant donné un tableau d’entiers t et une valeur entière v, déterminer l’indice i de t tel que t[i}=v
Algorithme simple :
int recherche(int cherche, int[]t){ for (int i =0;i<t.length;i++){ if(t[i]==cherche){ return i; } } return -1;}
Temps de calcul
Proportionnel à f(N)=N+1 avec N la taille du tableau
Possibilités d'améliorations dans un tableau trié
Si la valeur dans t[i] est plus grande que cherche, on retourne -1
⇒ n’améliore pas sensiblement les temps de calculs : toujours proportionnel à N, car dans le pire des cas on reste proportionnel à N
Au lieu de partir du début du tableau, on part du milieu :
int rechercheDecoupe(int cherche, int[] t){ if (t.length==0) return -1; int milieu= t.length/2; if (t[milieu]>=cherche) for (int i=0; i<milieu;i++) //0 à milieu-1 if(t[i]==cherche) return i; else for(int i=milieu;i<t.length;i++) //milieu à length-1 if(t[i]==cherche) return i; return-1}
On gagne en temps de calcul (pire des cas : N/2) mais ne passe toujours pas sous la courbe refLogarithmique
Algorithme de recherche dichtomique dans un tableau trié
int rechercheDicho(int cherche, int[] t){ int debut=0; int fin=t.length-1; boolean trouve=false; int milieu= (debut+fin)/2; while(!trouve && debut<=fin){ if (t[milieu]==cherche) trouve=true; else if (t[milieu]>cherche) fin=milieu-1; else debut=milieu+1; milieu= (debut+fin)/2; } if (trouve) return milieu; else return -1;}
Améliore la complexité expérimentale : temps de calcul proportionnel à log2(N)
Améliore aussi le nombre d’opérations dans le pire des cas (proportionnel à log2(N)
Complexité expérimentale
Etudier la complexité d'algorithmes incorrects est inutile
Détecter un algorithme incorrect :
Dérouler son exécution à la main sur de petites valeurs d’entrées
Le programmer et tester le programme de façon intensive (JUnit)
Comment tester intensivement un programme ?
Déterminer des petites valeurs pertinentes pour les tests
Par exemple pour l’ago de recherche : des tableaus de taille 0, puis 1, etc. tester quand l’élément est dans le tableau (début, milieu, fin) et quand il n’y est pas
Programmer les tests dans JUnit
- Utiliser les assertions `assertEquals`, `assertArrayEquals`
- Ne **jamais** effacer/commenter un test même s'il est réussi
Deux types d’étude de la complexité en temps
Le temps de calcul dépend de nombreux facteurs
la complexité intrinsèque de l’algo
l’efficacité du langage de programmation et du compilateur
la réactvité de l’OS
la vitesse de traitement du processeur
Donc, il y a 2 voies pour estimer les temps de calcul :
prendre tous les facteurs en compte : étude expérimentale
permet d’avoir une estimation précise
mais résultat non transposable pour un autre langage/système/machine
ne s’intéresser qu’à la complexité de l’algo : étude théorique
ne donne qu’un ordre de grandeur de la complexité
mais indépendant du langage/etc.
Etude expérimentale
Principe de l'étude expérimentale de la complexité d'un algorithme
on implante l’algorithme dans un langage particulier
on l’exécute sur des données de + en + grosses
mesure du temps d’éxécution
construction de la courbe d’évolution du temps de calcul en fonction de la taille des données
on peut prédire le temps de calcul pour une donnée de taille N
Exemple sur la fonction tracerRecherche
Teste les fonctions de recherche sur 20 valeurs de N =taille du tableau
N compris entre 0 et 106
Mesure le temps pour 1000 recherches pour chaque valeur de N
Bonus : vérifie la correction des r´esultats obtenus !
Trace les courbes correspondantes
Avantages de la complexité expérimentale
simple à réaliser
permet de prédire le temps, sur la même machine, pour d’autres N
Inconvénients de la complexité expérimentale
inutilisable si les temps de calcul deviennent trop longs
le résultat dépend de l’ordinateur, du langage utilisé, etc.
le résultat d´epend du choix des donn´ees… comment les choisir ?
données réelles ? prédiction valable sur d’autres données ?
données aléatoires ? mais les données futures le seront-elles ?
pire cas ? comment obtenir ces données ?
Etude théorique
Pour prendre en compte les données du programme
on estime la complexité en fonction de la taille N des données
on ne considère que le pire des cas
Utilisation du pire cas : si mauvaise complexité, l’algorithme peut être performant dans les cas + favorables
O(f(N)) : pour s'abstraire du processeur, de l'OS et du langage utilisé (compilateur)
on considère que toutes les opérations élémentaires (affectation, test d’une condition…) ont le même coût en temps
on ne s’intéresse qu’au nombre d’opérations élémentaires effectuées
Principe utilisé ici
Sélection des données pour une exécution dans le pire des cas
Déroulage à la main de l’algo sur une donnée de taille N, N+1, … (ou N x 2 si la complexité attendue est logarithmique)
Généralisation en une fonction f(N) dominant la complexité de l’algo dans le pire des cas
Avantages de la complexité théorique
indépendant du langage/système/machine
permet d’estimer la complexité quand la méthode expérimentale échoue (temps d’exécution trop longs)
Inconvénients de la complexité théorique
Donne une information partielle :
pire cas uniquement
abstraction des constantes qui peuvent être énormes
Estimer la complexité d'un algorithme (ici une fonction g)
On choisit des valeurs de paramètres de g pour une exécution pire cas
on sélectionne 2 valeurs dont les tailles sont proches mais différentes (par exemple N et N+1 ou N et 2 x N)
déroulages concrets de g pour ces 2 valeurs
à l’aide des déroulages concrets : déroulages abstraits
le long de chaque ligne verticale, on remplace toutes les instructions par un unique symbole ♦️
sur chaque déroulage abstrait on compte le nombre de symboles ♦️
on infère une fonction mathématiques f(N) qui pour N (=taille des paramètres) donne le nombre de ♦️ obtenus
La complexité de g est donc : O(f(N))
Choix des tests
Quels tests choisir ?
Utiliser son intuition : déterminer des petites valeurs pertinents pour les tests
Utiliser une méthode systématique pour choisir les tests : outil Pitest
Les tests logiciel sont utilisés pour montrer la présence de bugs, mais jamais pour prouver leur absence